Adverbial Presupposition Triggering Dataset
In this section, we present results from the ACL 2018 paper in addition to new results.
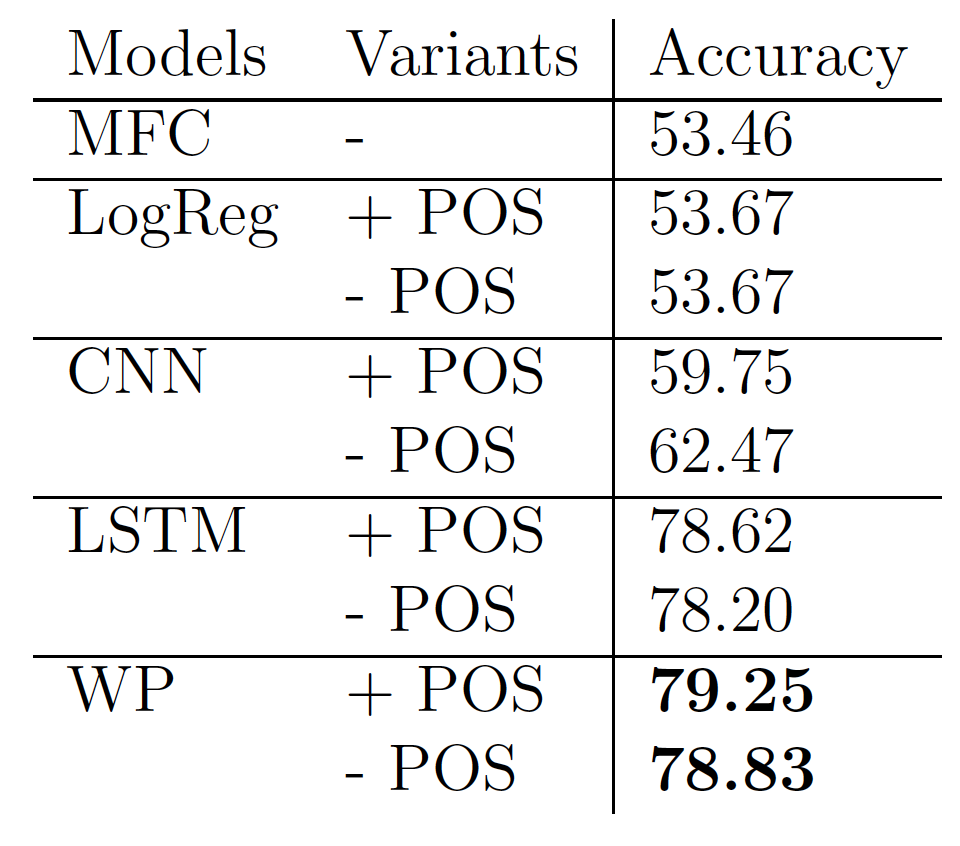
The first table presents the performance of various models, including our weighted-pooled LSTM (WP). MFC refers to the most-frequent-class baseline, LogReg is the logistic regression baseline. LSTM and CNN correspond to strong neural network baselines. Note that we bold the performance numbers for the best performing model for each of the "+ POS" case and the "- POS" case. For the analysis of the results, please refer to the ACL paper.
The first table presents the performance of various models, including our weighted-pooled LSTM (WP). MFC refers to the most-frequent-class baseline, LogReg is the logistic regression baseline. LSTM and CNN correspond to strong neural network baselines. Note that we bold the performance numbers for the best performing model for each of the "+ POS" case and the "- POS" case. For the analysis of the results, please refer to the ACL paper.
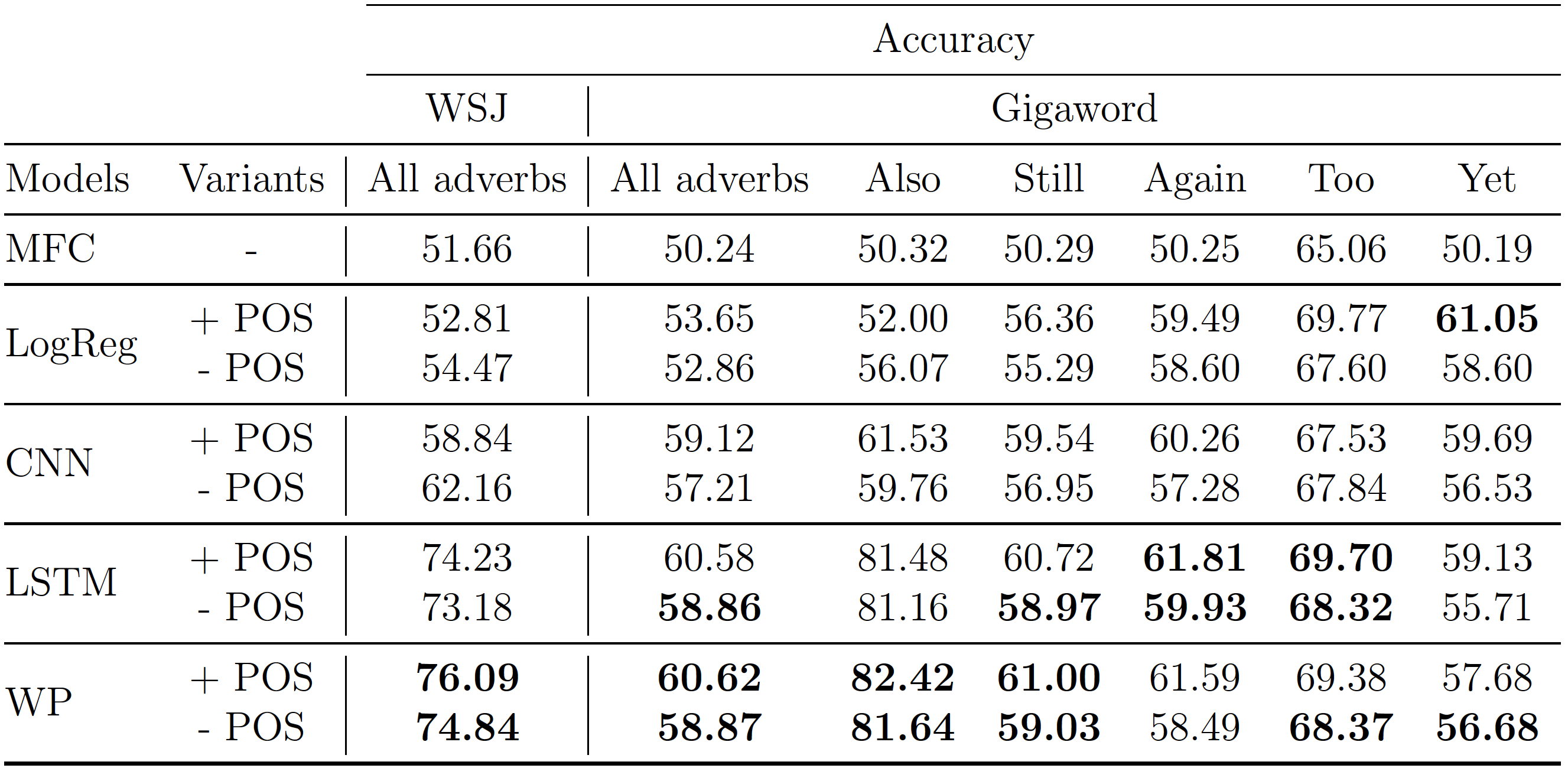
To validate the performance of our model on the newly annotated dataset, we ran our model and all baselines on the newly annotated dataset using the same hyperparameters and all appropriate settings as in the ACL 2018 paper. The results are shown in the table below: